Visualising metrics for the heck of it
Context
Having recently started using emacs’ org-mode the other day, an idea I had to keep myself engaged with it is to see how much I’ve added to org files over time. I previously set up a TIG stack, so I have the prerequisites to gather and visualise the data. Strictly speaking, it doesn’t even need the TIG stack- fifteen years ago I was collecting and graphing sensor data using lmsensors and gnuplot, which looked excellent.
I’m also sorting out a a bit of a backlog of (hledger) financial data, which makes for another excellent candidate- seeing progress in something (a habit, an instrument, a backlog) can be a helpful motivator.
Collecting Data
Telegraf input
Using telegraf’s [[inputs.exec]] input plugin seemed like the way to go (see eg this post in their forums about it). Paying attention to the format is important! I got an “Error in plugin: metric parse error: expected tag at” report in my telegraf log (journalctl -fu telegraf). The line protocol documentation explains the format.
The output format I went with was:
lineCount,file=/path/to/file.name lines=9001
--------- ----------------------- ----------
| | |
measurement tag (to filter on) dataand it worked thereafter:

for this I set the interval in telegraf.conf to “1m” (one minute) temporarily to get some measurements. I would recommend a more sensible interval, like “15m” or longer, depending on how often you think you’ll be working with an org file and how much resolution you *actually* need!
Collection script
It’s a short script:
#!/bin/bash
COMMONDIR="/path/to/org/file/directory"
FILES=("$COMMONDIR/main.org" "$COMMONDIR/work.org" "$COMMONDIR/home.org")
for FILE in ${FILES[@]}; do
linecount=$(wc -l "$FILE" | cut -f 1 -d ' ' || 0)
echo "lineCount,file=\"$FILE\" lines=$linecount"
done
This uses the array bash-ism.
Update: globs can be used in the array too and it Just Works™:
#!/bin/bash
# telegraf-file-linecounts.sh - print count of lines in files to stdout in format for telegraf collection
# see: https://docs.influxdata.com/influxdb/v2.1/reference/syntax/line-protocol/
ORGDIR="/path/to/org/file/directory"
JOURNALDIR="/path/to/journal/file/directory"
FILES=("$ORGDIR/*.org" "$JOURNALDIR/2021-*.journal" "$JOURNALDIR/2022-*.journal")
for FILE in ${FILES[@]}; do
linecount=$(wc -l "$FILE" | cut -f 1 -d ' ' || 0)
echo "lineCount,file=\"$FILE\" lines=$linecount"
done
Much better!
Filling in Historic Data
Finding old file versions with borg
Collecting data with telegraf is all well and good going forward, but what about historic data before I had this idea? Well, if you have a good backup system (you do have backups, right?) it should be straightforward to go through previous versions of the files and get the line counts at the time the backup was taken.
*: Actually I’d like an option to exclude ’empty’ archives from being mounted- if your backups go back 5 years, but you created the org file (or whatever you’re interested in) 18 months ago,
borg mountwill also create directories for the archives older than the file, but given thePATHdoesn’t match, they will be empty. It’s possible to test for this, but it’d be nice to have only archives with matched content shown.
I have borg, and it can indeed restore previous versions. In fact, there’s a special mode for that: ‘versions’ for borg mount.
versions: when used with a repository mount, this gives a merged, versioned view of the files in the archives. EXPERIMENTAL, layout may change in future.
https://borgbackup.readthedocs.io/en/stable/usage/mount.html
By specifying a --prefix, archives in the repo can be matched to the ones you know contain the file (useful if you have different prefixes in the one repo for different backup datasets); and by specifying a PATH you can limit the ‘extracted’ (ie mounted) paths to that of the file you’re interested in.
That’s all we need!*
We can use a borg invocation along the lines of the following:
borg mount -versions --prefix filteringprefix "backuprepohost:/path/to/backup/repo/here" /path/to/mount/archives/at path/to/document/of/interestwhich will give us a directory of matching archives mounted in /path/to/mount/archives/at.
We can loop over the directories, and exclude the empty ones via test:
if [ -z "$(ls -A /path/to/dir)" ]; then
echo "Empty"
else
echo "Not Empty"
fiThe downside is that the directory tests are slow, on the order of 1-2s. I’m guessing this is because my repo is ‘remote’ — though same local network! — and each test of the directory results in a remote query.
Inserting the historic data into influxdb
Given this is (hopefully!) a one-off, it makes sense to directly use the file-upload functionality of influxdb instead of collection agents or APIs. We can generate a file of influx line protocol data (or a CSV, but since we’ve already specified a line protocol for telegraf above, we might as well use that) for upload.
Note that the line protocol didn’t include the optional timestamp before- that data got filled in by either telegraf or influxdb at time of capture (I’m not sure which; it doesn’t hugely matter since it does the Right Thing either way). So when we write out the lines we will need to include that.
The line protocol uses Unix timestamps, and note this defaults to nanosecond precision. Since we’re dealing with historic backup data, it’s unlikely we will have nanosecond precision- my backups a notated to minute precision. We’ll therefore generate second-level timestamps and specify this when using the file upload:

Get file modification time as timestamp
So we have an influxdb line format for the entries, we know we can get historical versions of files from backups, the only thing we need is to give those historical data their timestamps.

I was getting down a shark-infested rabbit-hole — did you know that the shark is one of the rabbit’s lesser-known predators? — extracting the directory (which contains date+time) from the path, extracting the date+time part of that, then trying to find commands that had strptime. I thought I could use awk, but it only has strftime in its time functions.
Thankfully the ever-helpful Stephen Kitt had previously answered a question on the Unix&Linux SE with a helpful note:
“If you�re using GNU ls, you can use its --time-style option:”
ls -l --time-style=+%sThat got me exactly what I needed, in precisely the format influxdb wants- epoch seconds.
Neat!
An outline of a script to put it all together
We have everything we need, let’s put it all together:
#!/bin/bash
# influx-historic-linecounts.sh - print count of lines in files to stdout in format for influxdb
# see:
https://docs.influxdata.com/influxdb/v2.1/reference/syntax/line-protocol/
COMMONPATHS="path/to/emacs/org"
PATHS=("$COMMONPATHS/main.org" "$COMMONPATHS/ideas.org")
PREFIX=home
REPO="borghost:/path/to/backups/in/borg/"
MOUNTPOINT="/tmp/borgmount"
# Mount the archives
borg mount -versions --prefix $PREFIX "$REPO" $MOUNTPOINT $COMMONPATHS
for dir in $MOUNTPOINT/*/; do ## NOTE: slow! consider $MOUNTPOINT/*2022-04*/
if [ ! -z "$(ls -A $dir)" ]; then
for file in ${PATHS[@]}; do
filepath=$dir/$file
if [ -f "$filepath" ]; then
# parse dir name to get approx timestamp -- NOPE!
#dir2=${dir%*/} # strip trailing /
#dir2="${dir2##*/}" # get final part of path
#datestamp=$(echo "$dir2" | cut -d'-' -f 2-) # %Y-%m-%d-%H-%M
#timestamp=$(date --date="$datestamp" +%s) ## NB TZ
timestamp=$(ls -l --time-style=+%s "$filepath" | cut -f6 -d ' ') # much easier!
# ref:
https://unix.stackexchange.com/questions/575115/conversion-of-unix-file-listing-time-to-epoch-time
#echo "timestamp: $timestamp"
linecount=$(wc -l "$filepath" | cut -f 1 -d ' ' || 0)
echo "lineCount,file=\"/$PREFIX/$file\" lines=$linecount $timestamp"
fi
done
fi
done
# Done! unmount
borg umount "$MOUNTPOINT"
I left in some of the date&time foutering I did before finding --time-style as a warning to future folks.
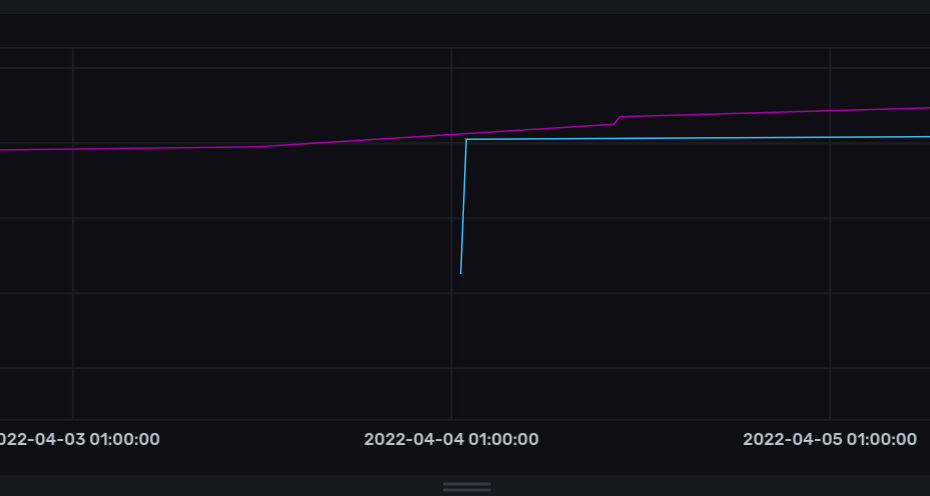
The Grand Result
After grabbing the historic data and navigating the Data Explorer in influxDB, we get a nice graph:

Not too shabby for a couple hours’ work!
Pingback: Toddler Steps With Emacs – Rob's Blog