In which I find out things have gone awry
Hey you! Yes, you! The one reading this. You have backups, right? Go check that they i) actually exist ii) are backing up at the right frequency iii) work. This is important, I’ll wait.
borg: Great for Backing Up
I’ve been using borg for backups for a couple of years now. It’s great- it does deduplication (saving tons of space!), only backs up what has changed (efficient! incremental!), and is somehow fun to use while doing so.
I wrote a script to take the backups, run as a systemd service each hour. All was well- it did error detection and emailed me when a backup failed.
But I had the occasion to check on the backups a couple days ago, and the latest one was from January. My first thought was disk space, but there was enough (albeit getting close to the limit). So I then checked the systemd output:
$ systemctl status periodic-backup
? periodic-backup.service - Take a periodic backup of directories
Loaded: loaded (/usr/lib/systemd/system/periodic-backup.service; enabled; vendor preset: disabled)
Active: inactive (dead) since Wed 2020-02-12 12:03:06 GMT; 45min ago
TriggeredBy: ? periodic-backup.timer
Main PID: 1168530 (code=exited, status=0/SUCCESS)
Feb 12 12:03:02 zeus systemd[1]: Started Take a periodic backup of directories.
Feb 12 12:03:06 zeus systemd[1]: periodic-backup.service: Succeeded.So the job was running and… succeeding, but not backing up?

Next step in diagnosis is to run the script manually, and make sure it still works. The script didn’t error, but it took a long time to complete- longer than a straightforward case of “large increment to backup since January”.
So I broke it down even further, and ran the borg command as written in the script. I got a prompt:
Warning: The repository at location ssh://bertieb@pandora/home/bertieb/backups/borg/zeus was previously located at ssh://pandora/~/backups/borg/zeus
Aha! It was waiting on input to proceed. One form is how the script access the repo, the other is how it is accessed from the command line. It’s a bit strange as the repo clearly didn’t move, and I’m not sure why it started treating the two differently.
Fortunately, borg has an environment var for just such an occasion: BORG_RELOCATED_REPO_ACCESS_IS_OK=yes
Monitoring
I asked in #borgbackup on Freenode about the issue, and folks said they had used a few things for independently monitoring backups:
I am indebted to Armageddon for mentioning the last one. While full-on monitoring with Prometheus looks interesting (especially in conjunction with grafana), it’s way overkill for my needs. Ditto Zabbix.
Healthchecks is a relatively simple tool which implements the concept, “we expect a ping/health-check at <such-and-such> a frequency; if we don’t get it then alert”.
Armageddon/Lazkani’s blog has a worked example of setting up Healthchecks to work with borgmatic (a tool to simplify borg backups). The official borgmatic ‘getting started’ guide is pretty good too.
The env vars in the Healthchecks docker image are used on creation; after they can be changed in
local_settings.py
I set up Healthchecks using the linuxserver Docker image — big note: the env vars listed there are used on creation, after that they can be changed in the data volume / directory under local_settings.py; that one held me up for a bit when i was trying to sort out email integration — and have added both my pre-existing scripts, and some new borgmatic backups.
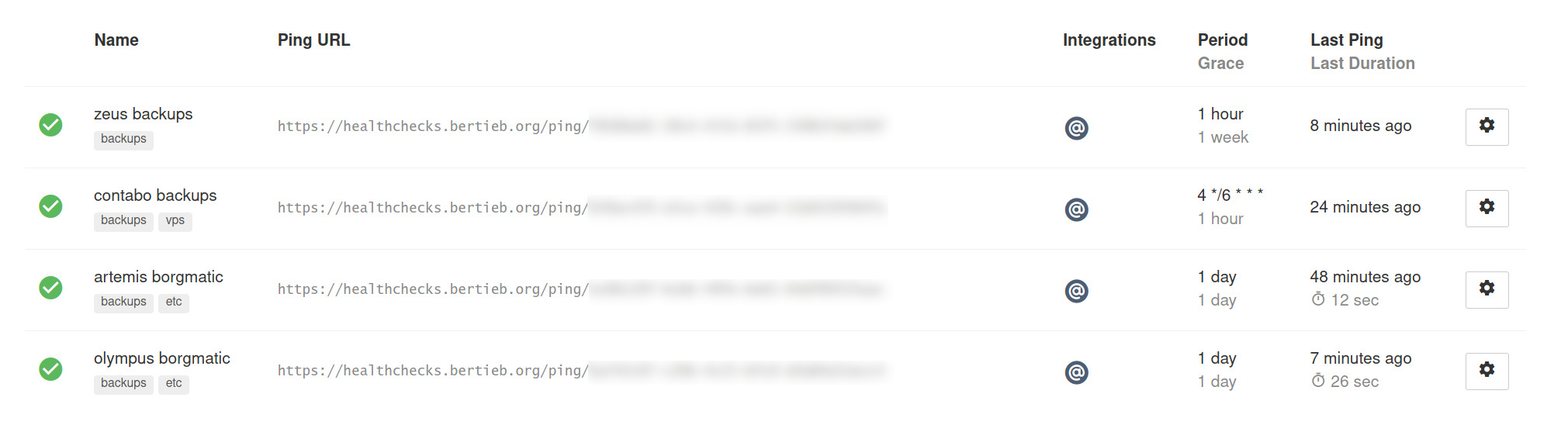
Looking good!
If you use the helpful ‘crontab’ format for the period, make sure to match the timezone, or you’ll get period emails saying the backup has failed. Ask me how I know…
Pingback: Reassess your backups! – Rob's Blog