if your backup cache takes more disk space that you have, you have a problem
tl;dr- gimme the bottom line
Hot on the heels of my last post about reinstating backups, I come with these suggestions:
- set a retention/pruning policy
- prefer more repos to fewer repos
and most importantly: periodically reassess your backup solution to make sure its working well!
Deduplication is great!
I’ve been using borg for backups for years. Before that I’ve used various other things, including a script of my own that used hard links; the details of which are lost to the mists of time. borg had everything I was looking for- simple, fast, and efficient thanks to deduplication. The last one is especially powerful- with deduplication, backups with few changes are cheap, and backups with no changes are ‘free’.
I used that to set a fairly aggressive backup schedule- backing up hourly or “every few hourly”. Since borg only sends files that have changed, once the initial backup is done, subsequent backups are super fast. All of this is laid out in more detail on the index page of the documentation.
This leads to some… interesting outcomes. From my website backups:
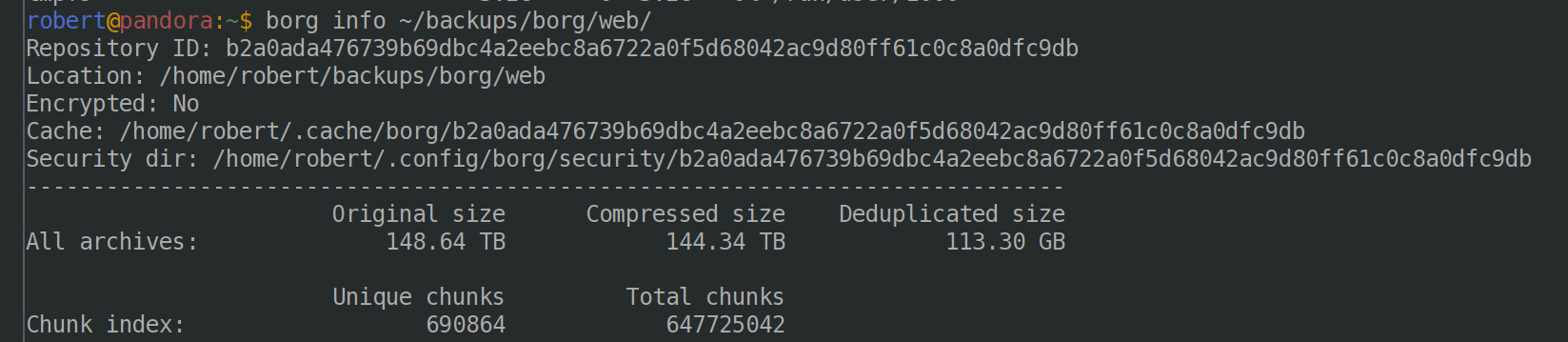
There are nearly 16 000 individual backups in that repo, and if you restored each and every one of them, you’d have nearly 150 terabytes of data. Thankfully, most of the data is the same; so the actual size is only 115-odd gigabytes, a few orders of magnitude (!!) reduction. Nice.
Many thousands of backups are… not great

So, you can have loads of backups; what’s the downside? Well, you remember that borg check I started running in the previous post? It’s still running.

Erf.
What about the cache from checking some of that repo plus another repo?
$ du -sh ~/.cache/ 32G /home/robert/.cache/
Oh, um.
There’s an issue that covers it. Basically, letting a repo grow to have a large number of backups is not a real great idea. Or as Thomas Waldmann put it on IRC, referring to the web repo in the image above:
16:05 <ThomasWaldmann> could be rather painful overall working with such a repo.It is rather painful.
The road to recovery
Enter borg prune (and its sibling, borg compact). This removes archives from a repo that are not specified for retention. I’ve had to use it before to stop my backups consuming all disk space- made more complicated by the fat that borg prune needs some space to work! The key is to remove (prune) a smallish number of archives at a time.
Using --archive-glob (which replaced --prefix) and a combination of --keep-*, where * is one or more of: hourly/daily/weekly/monthly/yearly I was able to start off the pruning process, removing around 3000 archives per run; keeping around 500. That’s likely more than I need, but better to have a buffer from which I can prune further.
From there I can run borg compact with the --cleanup-commits flag, as these archives were created pre-1.2 to free up space.
Before and after disk usage with one small pass of pruning and compacting the German webserver backups:
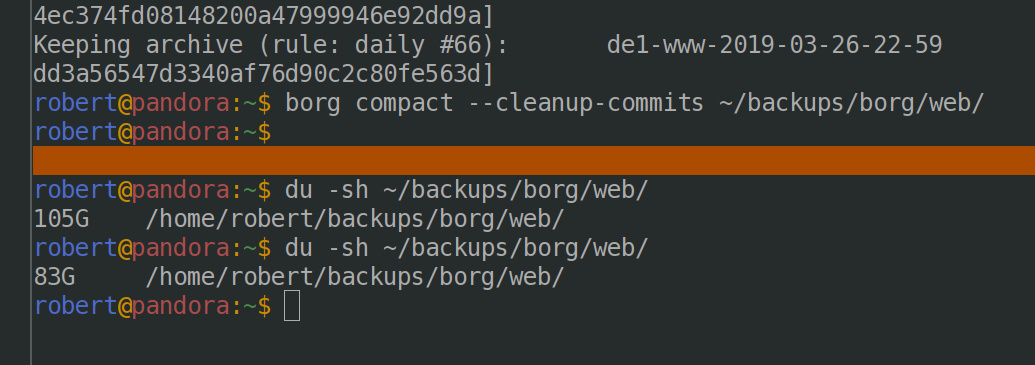
Nice. Now to do the other backups in that archive… which should really be in a separate repo since that makes several things simpler- like exclusive locks!
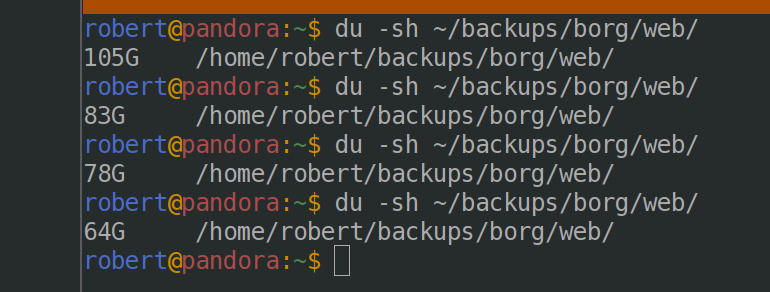
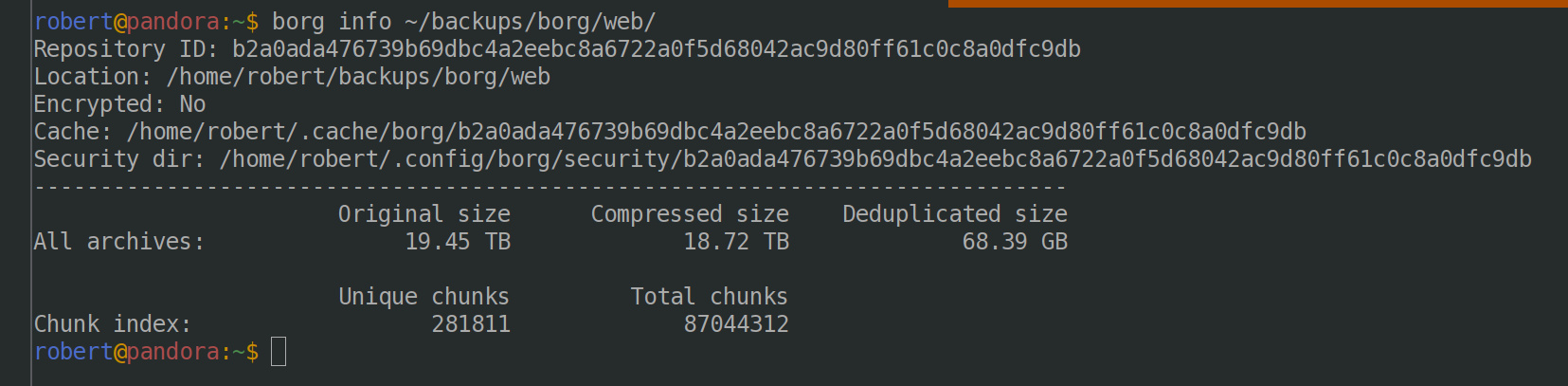
Getting the repo down to ~2k archives (from 160k!) really helps with the size! A before and after shot of the repo:

Moving forward
Back when I first started using borg I wrote my own scripts for backing up. They deal with alerting by email, monitoring (via healthchecks, which I discovered the last time I had an issue), plus for home and root they set up and tear down an LVM snapshot for backup consistency. What they lack is a pruning/retention policy!
For new machines (VMs, servers etc) I use borgmatic, which I discovered at the same time. It simplifies management greatly, and has configuration options for retention/pruning. I will either update my own scripts to include a borg prune and compact; or I might move over to borgmatic.
Pingback: PSA: Spacemacs freezing? Check your savehist file – Rob's Blog