Every day is a school day
We set out to use OCR to extract metadata from frames of the loading and ending screens of Deep Rock Galactic to use to fill in details of videos destined for YouTube.
In other words we went from:
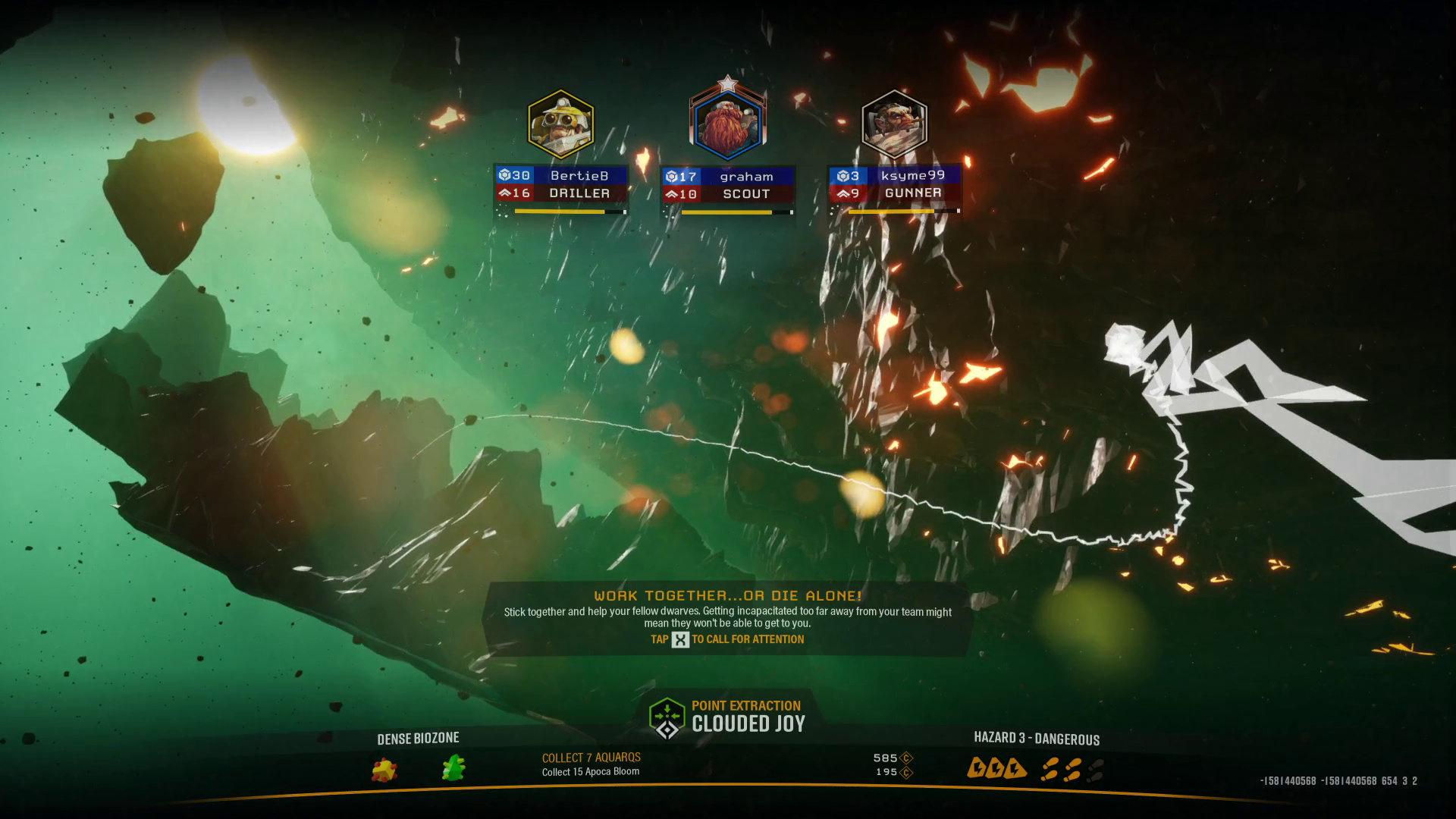
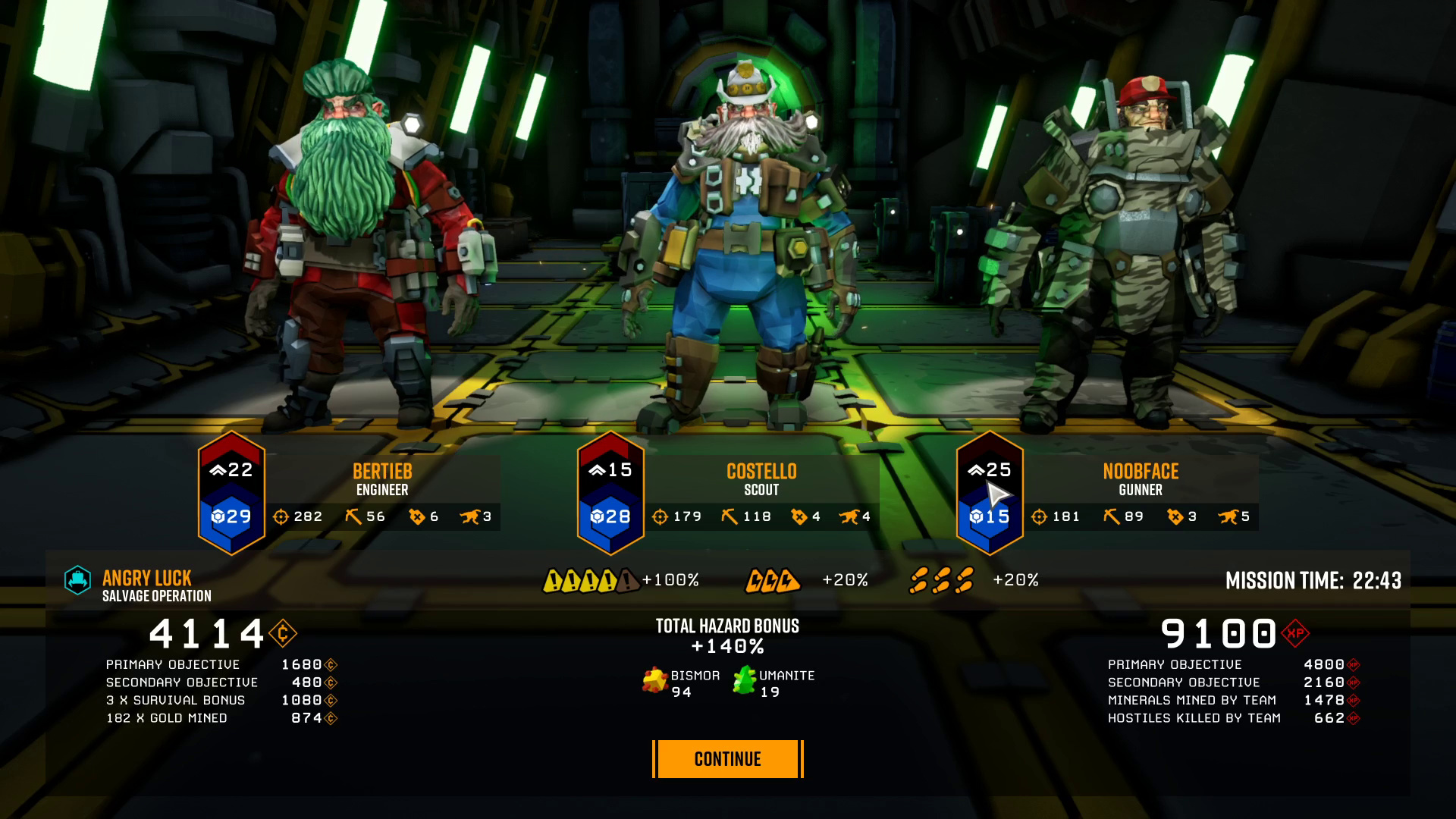
To:
Why?
It’s always good to reflect when you’ve done something. Did it go well, or not as well as expected? What did you hope to achieve? Did you achieve that? What has it changed? There’s as many ways to reflect as there are things to reflect on.
In this project I wanted to achieve a greater degree of automation with my video creation workflow. Partly because it would save me time:

The other reason is because copying text is no longer the provenance of monks in a scriptorium- it’s a repetitive, uncreative task. I enjoy spending time playing games with my friends, and those videos are there so that they and others can relive and enjoy them too; spending time copying text is not a good use of my time.
However, there’s a more pertinent image for this sort of task:

There were 47 videos in the test batch. Let’s say that I would have spent five minutes per video copying across the title, writing a description, figuring out the tags and such; doing that manually would have taken 235 minutes, or nearly four hours. That might sound like a lot, but it’s certainly less time than I worked on the automation.
The automatic OCR will have ongoing benefits – there are more videos to process.
But the best part is that I learned. I learned about tesseract and OCR, a bit about OpenCV, and honed my python programming skills.
Lessons Learned
OCR is good enough to extract text from video stills. I assumed this, but it is good to have it confirmed.
Cleaning up images makes a huge difference to OCR accuracy. I could probably have improved detection in the opening image to use just that if I had cleaned up earlier in the process; but using both loading and ending images gives more metadata, so it worked out okay.
It’s really easy to leak file descriptors. Late on, when I went to test with a wider variety of videos, I ran into this issue “OSError: [Errno 24] Too many open files“. Instead of using tempfile.mktemp, which unexpectedly kept the fd, I had to use tempfile.NamedTemporaryFile. That one took a bit of hunting down as it looked like pytesseract was failing, and coincidentally they had a couple of issues in previous versions due to the same issue (mktemp vs NamedTemporaryFile)! Most confusing.
What Would I Do Differently?
Implement automated testing. This would have hugely helped in the refinements stage, where regressions in detection accuracy occurred as I refined. There were a couple of reasons that put me off at the time, but they were more excuses than reasons:
- this was a “quick and dirty” attempt to get a tool working, refinements to it can come later
This an old, old excuse; proved false time and again. It’s sometimes phrased as “This is just a temporary fix, will do it properly later” and other variants. What it boils down to is “We’re going to do this the ‘wrong’ way for now, and change it later”.
It sounds fine, if you actually sort it later, but invariably that doesn’t happen. Time and effort have to be focused somewhere, and it’s a harder sell to redo something that “works” (however hackily) than to implement a new feature, or get a product out the door.
Here it was even worse: doing that work may well have improved the “quick and dirty” process. - the frame extraction + OCR processes aren’t quick, and tests should be quick to run; it’s also hard to break apart the pipeline
This excuse is on slightly firmer ground, but not by much! It’s true that these things take time, but they can be broken down to components and tested individually using sample images (for example).
It might not provide the coverage of a real life full data set, but it’ll catch the worst of regressions.
Future Improvements + Directions
Use only a start or end frame if one is missing. At the moment a video is skipped if either the start or end frame is not detected. That leaves the video to be done entirely manually- we could get at least some of the metadata from without the other.
Detect in-game menu screen. For times when I hit the record button too late (or OBS takes too long to spin up), I could go into the menu which has a couple of bits of metadata. I would need to remember to do this, but I usually realise I’ve hit record too late. Combined with the above improvement, we could increase video coverage.
Expand OCR to other games. This is non-trivial but an obvious way to go. Killing Floor 2 is the likeliest next candidate as at the moment it’s the one we play the most and also has metadata to capture.
Consider a further automated pipeline. As it stands, I have to run the program against videos manually; not a big deal. But a tool that detected new videos, automatically runs the OCR tool against them and puts them and the JSON output in a convenient place (� automatically uploading them to YouTube) would make the process more streamlined. This may be beyond my own need or indeed tolerance- I could see it being potentially frustrating if I wanted to manually handle a video differently.
Overall though, I am happy with how the tool turned out.
Pingback: Extracting Info From RoR2 Videos: Concept – Rob's Blog