In which things aren’t quite as smooth as they seem
We’ve been using OCR to extract metadata from Deep Rock Galactic loading and end screens, and we’re at the stage of doing most of that automatically.
I was quite pleased with the progress we’ve made. But as so often is the case, I went to demo the program and it failed. The mission name seemed to be an issue. I had a look and the image the end_screen_detector had supplied was very dark- it managed to find one on a fade out; though this was too dark for decent OCR.
Improving Detection
To solve that, I used ImageStat to pull out the mean pixel value, and eventually settled on giving the image an extra point for its score if it was over a threshold. For those paying close attention, this also mean that I had to change my “no image found” logic to trigger on values <= 1, as a bright frame with no elements matched would score 1. Acceptable.
A Bit of Visual Debugging
However, I continued to run into issue with the mission name. After debugging some individual images, I decided to simply show() the region that was being fed to tesseract across a number of input videos:
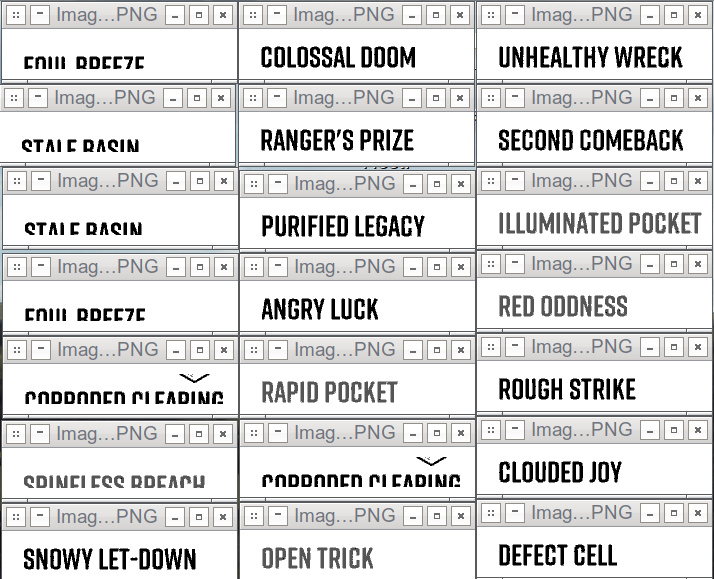
As I’ve said before: “ah”, and “hmm”. It seems as though the mission text can move, after all. It’s not enough that a cursory glance would see it – maybe ~10-15 pixels – but enough to completely butcher the text for OCR purposes.
I’m not sure if there’s a way to know a priori in which position the name will be – assuming there are only two possibilities, for now – so we’ll have to do something similar to what we did for the player names, which can also move.
Using Confidence and Pixel Nudging
For the names we relied on detecting a known name, but perhaps there’s a better approach here?
image_to_data Returns result containing box boundaries, confidences, and other information
This looks like what we want! We’ll send two regions (for now) to pytesseract, and take the one with the highest confidence; then send that text to be hard-cast to the known possible mission names. I say “for now” as if there are two ways that we can see, there may be more that crop up through testing, so I am writing this to work with any number of mission name regions.
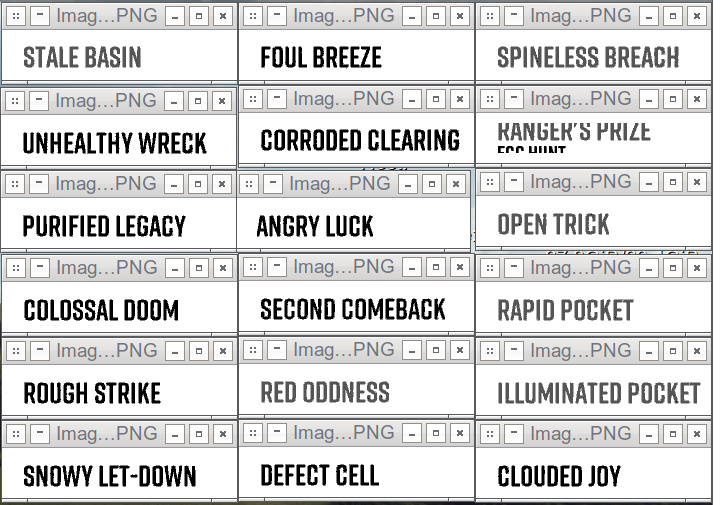
A few pixels difference can have a huge impact on accuracy!
Much better! Although Ranger’s Prize seems to have flipped over to using the worse of the two, it still is detected as “Ranger’s Prize” by OCR, so I’ll let that pass for now.
We could use the ‘best confidence’ approach to improve the detection of names, and help reject over-detections. It could probably also be applied to mission types:

Looks like there’s also a bit of movement on the mission type. Let’s see if we can improve things here too. While the detection rate is good – only error is the Elimination being cast to Egg Hunt – we can improve this which helps when we expand to even more videos.

Much better.
I also ripped out the guts of name matching so that it could use the confidence method for those. They took a little more thinking about because of an extra dimension (n name regions to look up instead of one region) but that was changed over and retains the Levenshtein distance of <= 2 for clamping OCR output to a name.
Law of Unintended Consequences
However, that unearthed a side-effect: the confidence of 2 name detection will always be higher than 4 name detection, even when there are 4 names as the middle two names occupy the same space for two players and four players. So instead of using the max value for confidence, we can apply a threshold instead, and if the detection for 4 names is over that threshold we can apply that.
Digging deeper, I found that the confidence varied hugely between the 4-name and 2-name detectors for the same word in the same position:
... 'nametext1': 'graham', 'nameconf1': 26.0 ...
... 'nametext0': 'graham', 'nameconf0': 96.0 ...Same text, same position, *slightly* different bounding box by a few pixels. It’s possible that the 2-player name boxes are off by a few pixels (though if that was the case, the 4-player detection should be better, not worse!); but it’s more likely that my own box drawing had differences between the two scenarios, as that was a manual process.
As noted: a few pixels can make a huge difference in confidence and accuracy of OCR.