We’re using OCR to extract game metadata from Deep Rock Galactic videos. We’re now at the point where if we give our script two images – one of the loading screen, one of the end screen – it does a pretty good job of pulling out the information.
Now we need a way to pull out the images automatically. Since the loading and end screens are a variable distance but close to the start and end of the recording, we need to find the screens rather than rely on a fixed time.
Off the top of my head, two potential approaches spring to mind:
- use OCR to detect known elements of each screen
- use trained CV to recognise the screens
While the second option sound fun and interesting, it’s not something I know a lot about. Perhaps we can return to that at some point. For now we’ll try OCR. Start at the beginning and seek forward, and start at the end and seek backwards. For OCR, we want something that will be i) reliably read and ii) doesn’t move, ideally.
End Screen
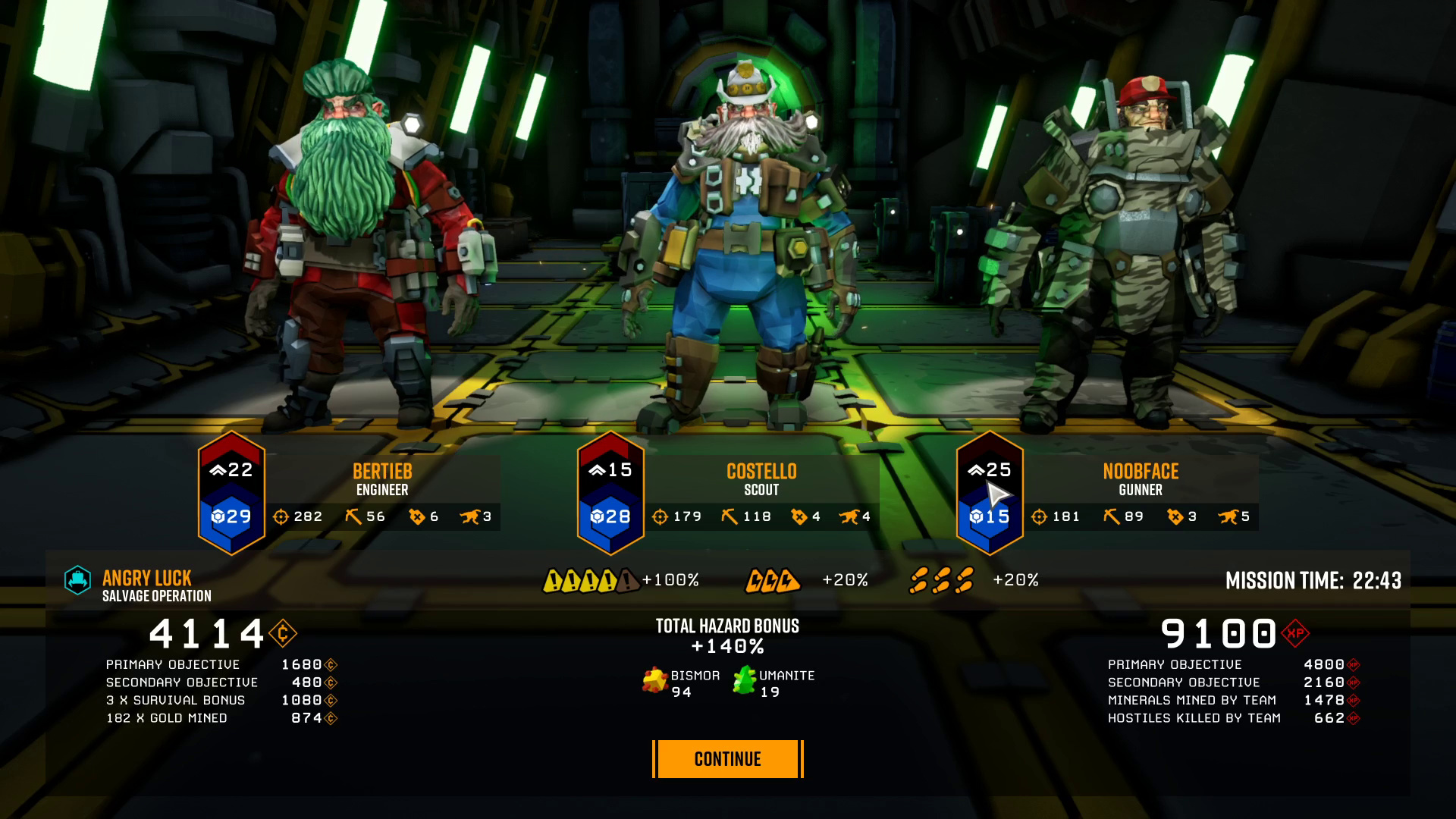
A couple of elements jump out as possibilities: the “MISSION TIME” string on the right is large and clear; “TOTAL HAZARD BONUS” is also reasonably clear, and the CONTINUE button looks like it is in a fixed position.
Loading Screen
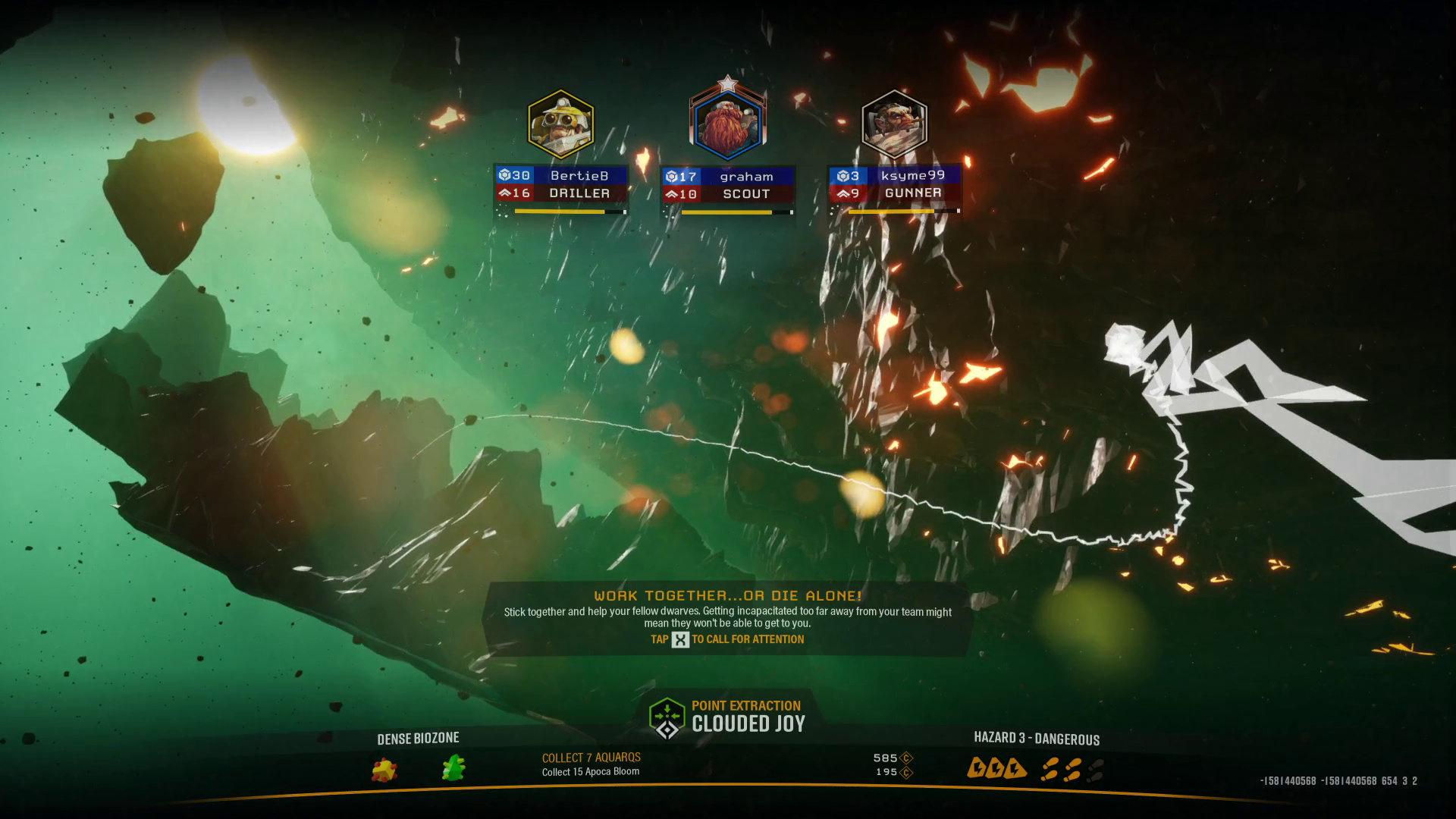
The loading screen is trickier. Most of the elements look dynamic. Of the text, the mission name is probably the clearest, and we do have a list of possible mission names. The player names and classes are there- I should be in all of my videos, and we can also test for the presence of “DRILLER/SCOUT/GUNNER/ENGINEER” somewhere in the top quarter of the image.
Quick OCR
The approach used sets a start time, an end time and a step, generates frames for those, then OCR’s the frames and scores them based on what is present.
In the case of the loading screen, recognised players names and classes are scored, and then the frame with the highest score is picked. A score of 0 means the detection has failed, for example if the time period in the video does not contain a loading/ending screen.
This approach has the advantage of picking the best frame; though it is slower than picking the first acceptable frame. Minimising runtime isn’t crucial here however, as uploading the video takes orders of magnitude longer than the time to run the script. We could exit as soon as a frame scores 8 (four players names and four classes)
In the case of the ending screen, we match on “MISSION TIME:”, “TOTAL HAZARD BONUS” and “CONTINUE”, each word here scoring 1 point. Here, because the elements are known in advance and should always be present, we can have an early exit for a frame that scores the maximum of 6.
Putting Detection and OCR Together to Test
Our previous version took images to work on as arguments, which was fine when we were testing, but now we’re testing videos, so the code needs tweaked to handle that.
Throwing a bunch of videos at it, showed a couple of issues. One video had OCR fail on the mission name, so I tweaked the box and applied a bunch of enhancements (grayscale, posterize, invert, autocontrast, border) to get the text OCR’d correctly.
I also changed my name checking list to have the expected version of the names, rather than lower case, for the purposes of doing some Levenshtein distance checks. This led to some name combinations not being detected, so the any() logic needed changed:
if any(n in [name.lower() for name in names] for n in namecheck):Became:
if any(name.lower() in [n.lower() for n in namecheck]
for name in names):Also, remember a few paragraphs when I said “time taken doesn’t really matter”, well it does when you’re making changes and retesting! When I set up the list of 10 videos to collect output from, I had to do other things a few times. As ever, the truth can be found in xkcd:

The output we got with minimal changes is pretty good:
file names mission_type biome hazard mission_name minerals
0 2019-10-13 21-41-44.mkv [BertieB, graham, MaoTheCat, ksume99] Mining Expedition Radioactive Exclusion Zone Hazard 3 Open Trick [Umanite, Enor Pearl]
1 2019-10-13 22-08-16.mkv [BertieB, graham, MaoTheCat] Mining Expedition Glacial Strata Hazard 3 Purified Legacy [Umanite, Magnite]
2 2019-10-14 20-06-55.mkv [BertieB, Costello] Salvage Operation Magma Core Hazard 4 Unhealthy Wreck [Magnite, Croppa]
3 2019-10-14 20-54-49.mkv [BertieB, graham, Noobface, Costello] Point Extraction Salt Pits Hazard 4 Rapid Pocket [Bismor, Enor Pearl]
4 2019-10-14 21-16-24.mkv [BertieB, Costello, Noobface] Salvage Operation Salt Pits Hazard 4 Angry Luck [Umanite, Bismor]
5 2019-10-15 18-04-10.mkv [BertieB, Costello] Egg Hunt Fungus Bogs Hazard 4 Ranger's Prize [Croppa, Jadiz]
6 2019-10-15 18-26-15.mkv [BertieB, Costello, graham] Mining Expedition Glacial Strata Hazard 4 Second Comeback [Jadiz, Bismor]
7 2019-10-17 19-14-51.mkv [eVNS, BertieB, Costello] Egg Hunt Radioactive Exclusion Zone Hazard 4 Colossal Doom [Umanite, Enor Pearl]
8 2019-10-17 19-41-38.mkv [BertieB, Costello, graham] Egg Hunt Fungus Bogs Hazard 4 Illuminated Pocket [Magnite, Enor Pearl]
9 2019-10-17 20-13-07.mkv [BertieB, Costello, graham] Egg Hunt Crystalline Caverns Hazard 4 Red Oddness [Umanite, Bismor]
There’s a couple foibles: ksyme99 is detected as ksume99 in 0, and there’s a spurious detection of ‘eVNS’ in 7. This suggests name detection could be improved, though recall we weren’t able to hard-cast the output as there’s the possibility of unknown player names. However, we can use our good friend Levenshtein distance to fix off-by-one-character issues like the above.
for name in names:
if name in namecheck: # Already good!
continue
else:
for known_name in namecheck:
if distance(name, known_name) <= 2:
names.remove(name) # remove the 'bad name'
names.append(known_name) # add the known good oneAnything with a Levenshtein distance of 1 or 2 gets clamped to a known player name. This sort of optimisation is very helpful if you have a set of regulars that you play with, but less so if every game is with different people.
This gets us some decent output! The spurious detection is an issue, and one that could be mitigated by some careful DSP. But the output is usable, so we’ll move on to the next step: integrating with our existing workflow!