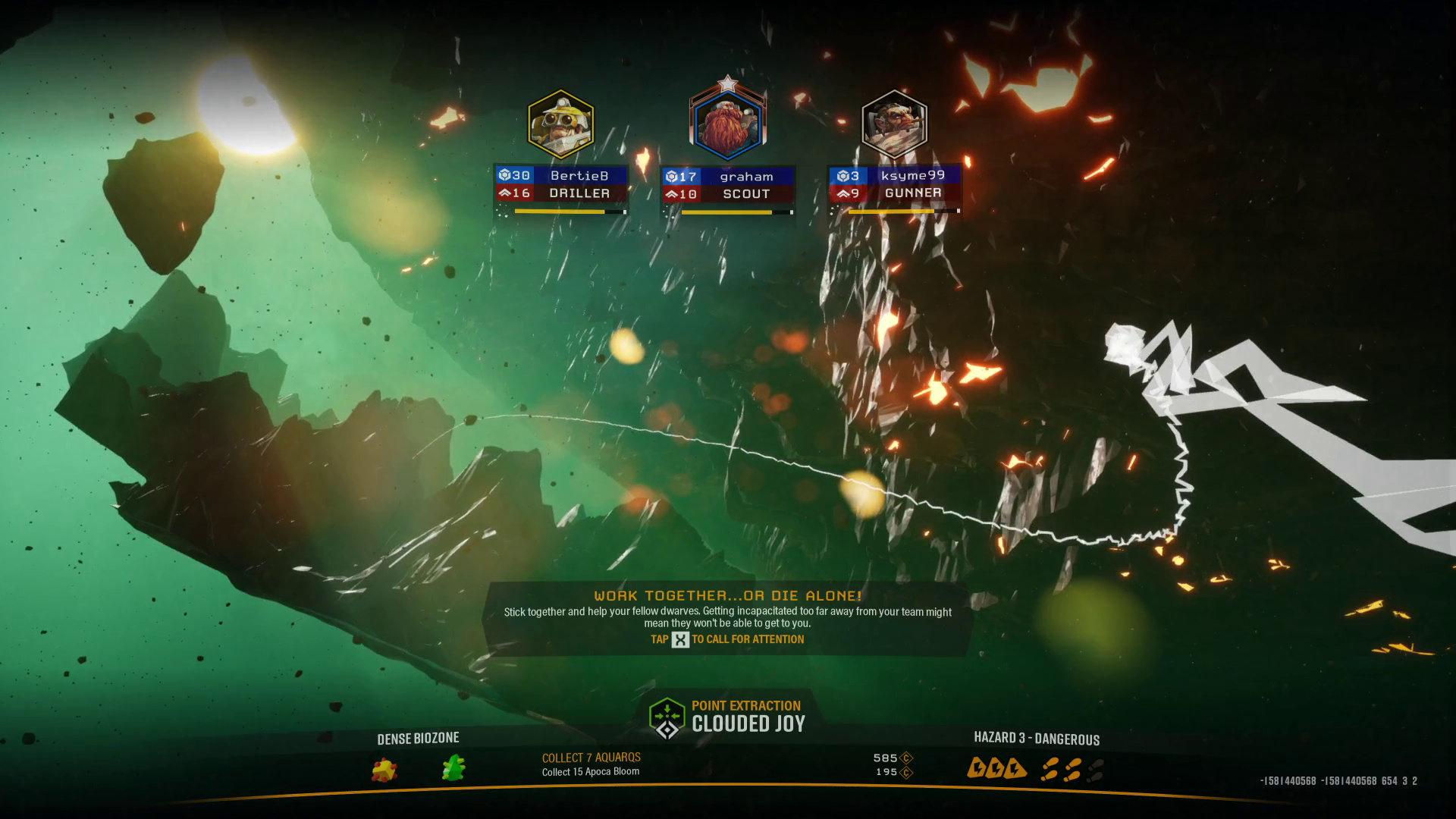
Last time, we decided that Deep Rock Galactic is a game which is ripe for extracting video metadata from, thanks to it’s beautiful loading screen filled with information:
For OCR we need look no further than tesseract! It’s open source, under development (since 1985 no less!) and easy to install in Arch.
Let’s jump right in and point it at the image above, default settings.
$ tesseract drg-ocr-1.png stdout
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 189
Y
I
7 A
WORK TOGETHER...OR DIE ALONEY
Sticktogether and help your fellow dwarves. Getting incapacitated too far away from your team might
�mean they won' be able to getto you.
TAP [ 70 CALL FOR ATTENTION
POINT EXTRACTION
CLOUDED JoY
LA HAZARD 3- DANGEROUS
> COLLECT 7 AQUARQS ECEES
' x Collect 15 Apoca Bloom [ErE hhb :: �
-1581440568 -1581440568 654 3 2Oh, er. Now, for an image that’s a still from a video that’s not too bad, actually! It missed the names, classes, and biome, and thinks “Alone!” is “Aloney”; but on the plus side it got the mission type, name, objectives and hazard level.
Not a bad start, and I reckon we can clean that up when we get to actually processing the image with a bit of smarts.
Perhaps using a smaller region would help?
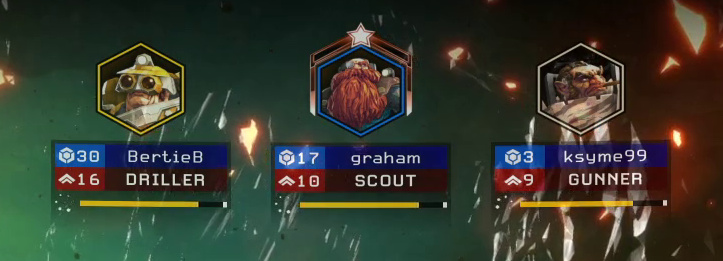
Let’s see:
Detected 34 diacritics
N
� /� e I
4Bert1ea j 3 Eraham
DHILLEH b scout
' /x�./f,,
" // II/ sEh, sort of? Given we’ve done no processing or cleanup, tesseract isn’t doing terribly.
Let’s make it real easy!
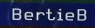
$ tesseract drg-ocr-name-bertieb.jpg stdout
BertieBBeautiful.
We haven’t done any of the things that can improve tesseract’s accuracy, like image clean up or changing page segmentation mode. Despite that, we’re getting good, usable results from simply cropping.
The next stage is automation!