
Reassess your backups!
if your backup cache takes more disk space that you have, you have a problem tl;dr- gimme the bottom line Hot on the heels of… Read More »Reassess your backups!

if your backup cache takes more disk space that you have, you have a problem tl;dr- gimme the bottom line Hot on the heels of… Read More »Reassess your backups!

(when you move them) Context A while back I moved my home server from Xen (for host ‘OS’) with mdadm + LVM (for raid6 storage);… Read More »Reinstate your backups!

January wrap-up Since this doesn’t appear in my own previous ‘tips to myself‘ I’m documenting it to myself here: The option for disabling wrapping is:… Read More »pandoc micro tip: disabling line wrap / newlines
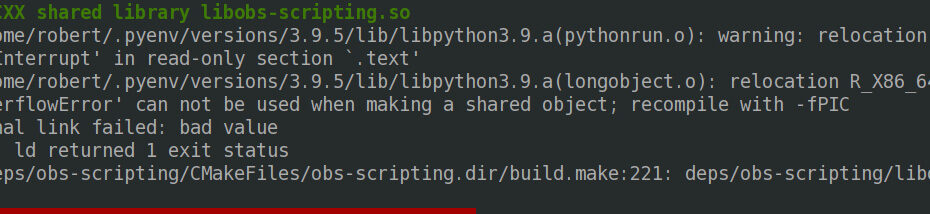
Why do I need to change the pilot in command anyway? tl;dr: if and only if your problem is the wrong pyenv being used when… Read More »[solved] Building OBS in Linux: “recompile with -fPIC”
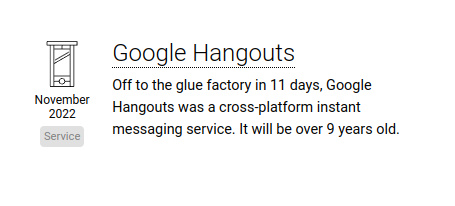
If you’re still using Google Hangouts, no you’re not About a week ago I ran into a weird issue in bitlbee, which I raised in… Read More »PSA: Hangouts is deprecated and no longer works in bitlbee

Get out of my house! tl;dr Set is_active to f in the database, then run the ‘delete all unactivated accounts’ task (? jump to postgres… Read More »Mass-delete / remove / purge users in Gitea
going public Context Download (direct link to JSON) This file can be imported via Dashboards ? + Import (on the left hand panel), then ‘Upload… Read More »Monitoring ZFS with InfluxDB & Grafana: Publishing and Reflection (Part 5)
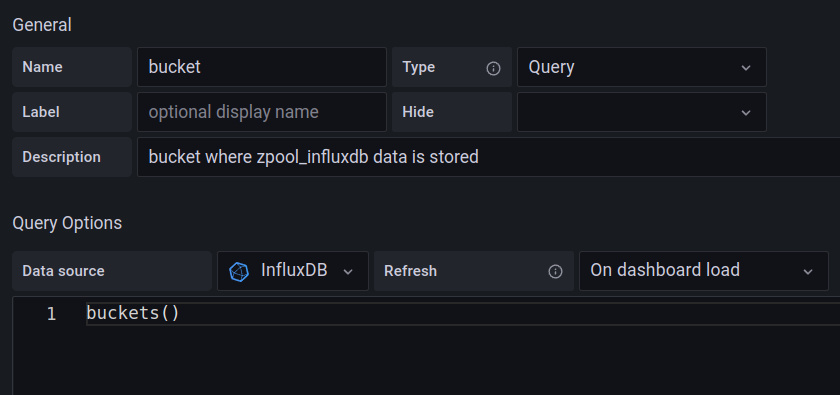
getting it out the door Context Adding a Variable for Bucket Selection In Part 3 we updated the dashboard’s variables for host and poolname to… Read More »Monitoring ZFS with InfluxDB & Grafana: Tidying Up (Part 4)
the hourglass of time runs on Context I had use for an animated gif of an hourglass in a video — I had a pause… Read More »Making an animated gif transparent + recolouring + adding shadow using imagemagick
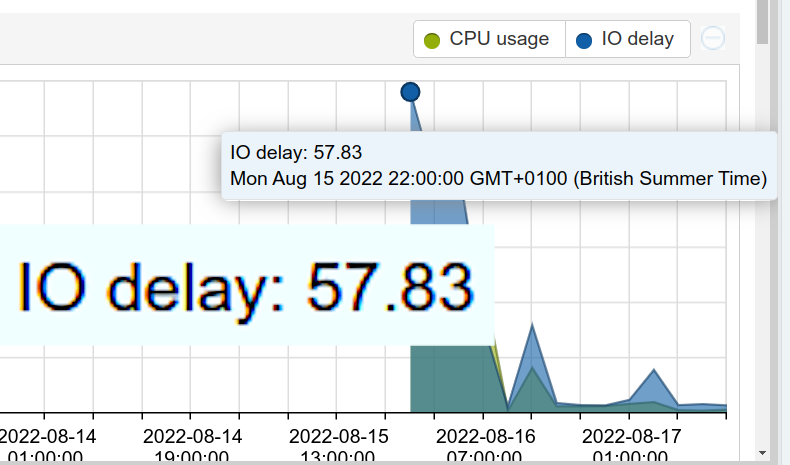
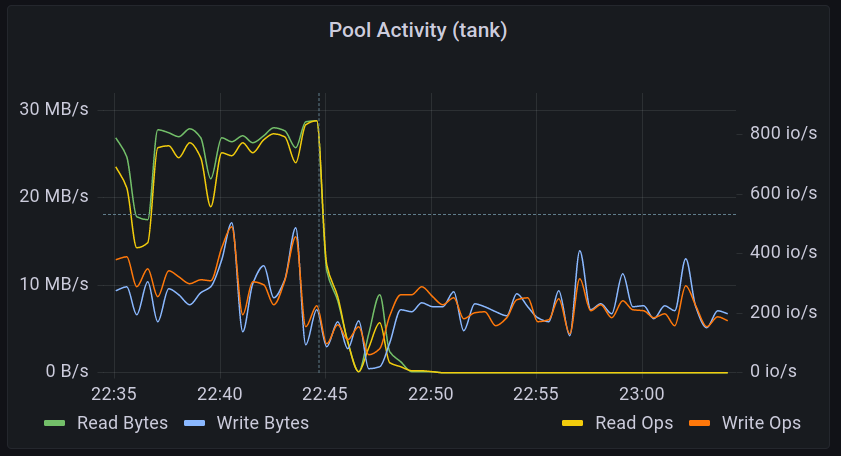
quick or slow Context + zpool iostat Recently I noticed some high IO delay on a proxmox host: Naturally I turned to resident ZFS expert… Read More »Monitoring ZFS Latencies in Proxmox (Part 1)