
Extracting Info From RoR2 Videos: Concept
Decipherer of Symbols Context I love Risk of Rain (RoR), and it’s sequel Risk of Rain 2 (RoR2) even more. They fit all the pieces… Read More »Extracting Info From RoR2 Videos: Concept

Decipherer of Symbols Context I love Risk of Rain (RoR), and it’s sequel Risk of Rain 2 (RoR2) even more. They fit all the pieces… Read More »Extracting Info From RoR2 Videos: Concept
☑? ? ? (see footnote) tl;dr: there are two simple js / jQuery command you can run in the browser dev console to quickly uncheck… Read More »Speeding up unchecking the ‘notify subscribers’ button in YouTube
From ‘one-off’ to ‘actually I need to do this again…’ Context My often-talked-about video workflow has a bunch of useful features. For example, if I’ve… Read More »Converting Vim Macros to Functions

Working on the backlog Background Back in the summer of 2019 I streamed a Europa Universalis IV campaign as Aragon, where I went for the… Read More »Getting Aragon Videos Out
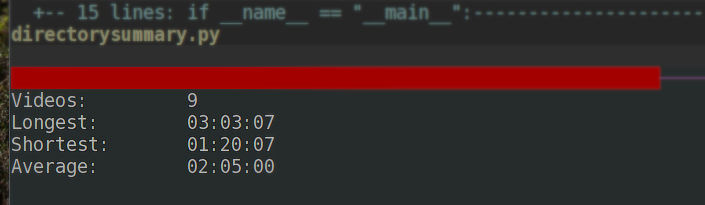
Information is power To process my Subscriber Crown videos for YouTube, I needed a little bit of information. I tend to split up longer videos… Read More »Quick Scripts: Summary of Video Directory

Yet another thing ffmpeg can do Streaming a camera to YouTube came up in chat the other day. It’s not something I’ve ever had cause… Read More »Streaming a Phone (or IP) Camera to YouTube
From the Department of Wordy Titles I have a set of tools that I have written to make interacting YouTube simpler, more straightforward, simplifying my… Read More »Including Contemporaneous Info in my YouTube Workflow
More ‘exactly what it says on the tin’ A couple weeks ago, I had to renumber some Hunt: Showdown videos in a playlist: Well, now… Read More »Rescheduling YouTube Videos using Python
Doing exactly what it says on the tin I’ve been playing Hunt: Showdown with friends recently. With these kids of things I like to stream… Read More »Renumbering Ordered Videos in a YouTube Playlist with Python

Jack Howitzer as Jack Howitzer in ‘Jack Howitzer’ I played some GTA V: Online the other night — my three word review: ‘fun but clunky’… Read More »Take 2 Claims ‘WZLJHRS’