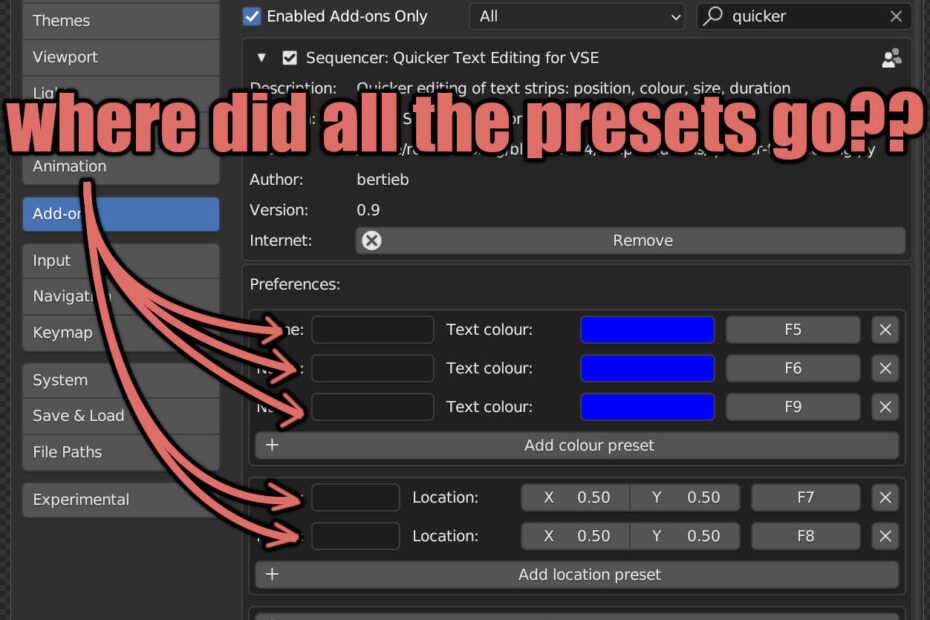
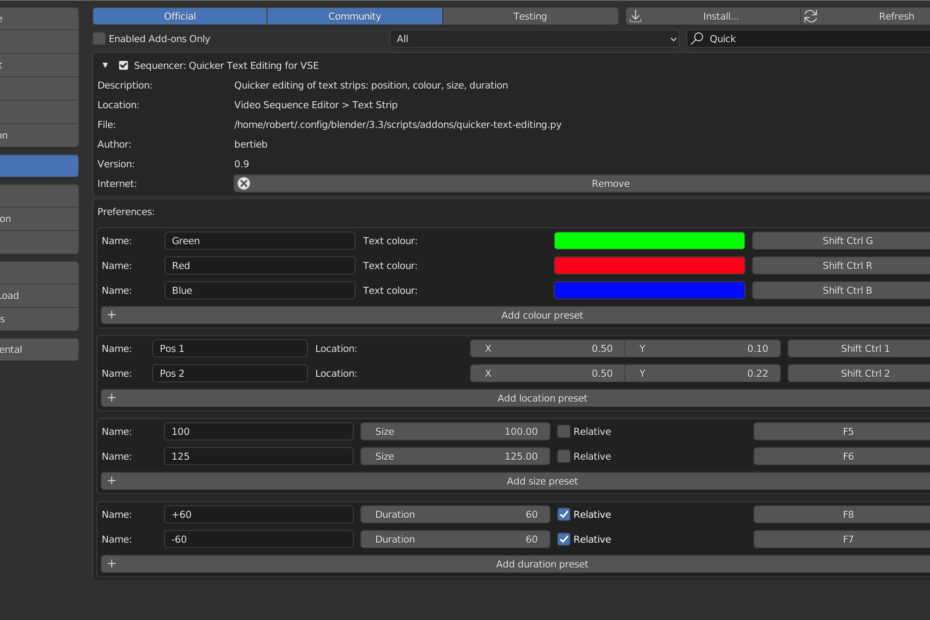
Quicker Text Editing in Blender (Part 9): Prototyping Appearing Text

It… is… appearing… one… word… at… a… time Context I use Blender VSE to make videos, but I want to make the tedious bits less… Read More »Quicker Text Editing in Blender (Part 9): Prototyping Appearing Text