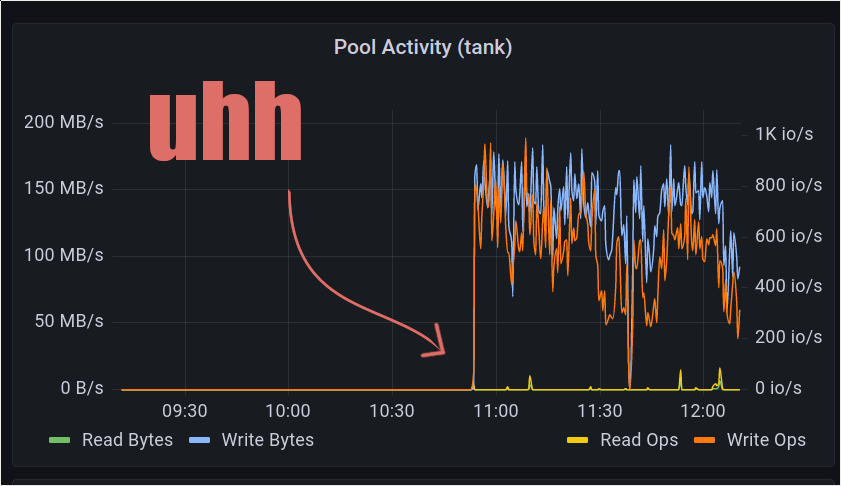
Fix your backups!
I thought we did that already Update: Helps if you actually fix the underlying problem so it doesn’t happen again a week later. D’oh. As… Read More »Fix your backups!

I thought we did that already Update: Helps if you actually fix the underlying problem so it doesn’t happen again a week later. D’oh. As… Read More »Fix your backups!

if your backup cache takes more disk space that you have, you have a problem tl;dr- gimme the bottom line Hot on the heels of… Read More »Reassess your backups!

(when you move them) Context A while back I moved my home server from Xen (for host ‘OS’) with mdadm + LVM (for raid6 storage);… Read More »Reinstate your backups!
In which I find out things have gone awry Hey you! Yes, you! The one reading this. You have backups, right? Go check that they… Read More »Monitor Your Backups!
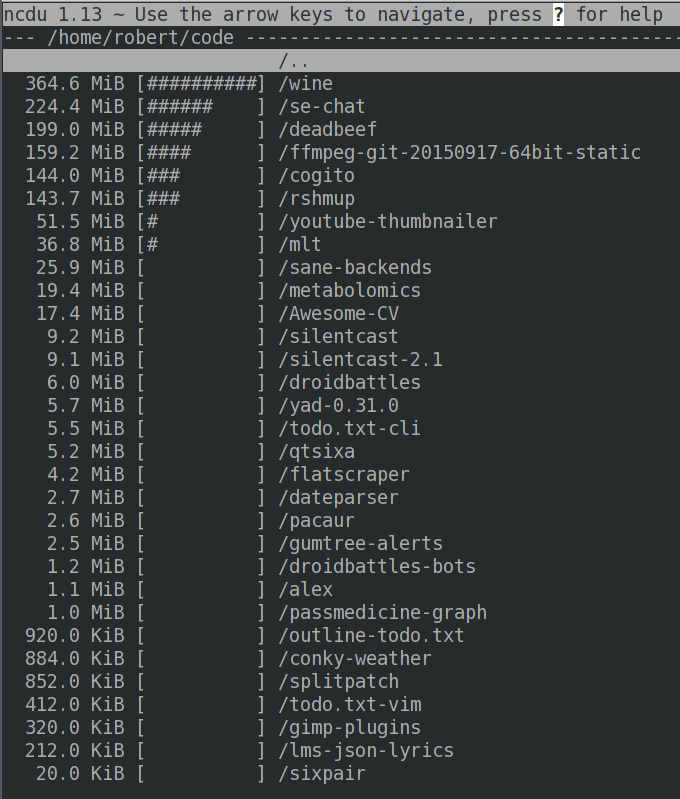
tl;dr: Picking what you are going to back up helps (i) keep the backup space usage minimal (ii) helps to inform choice of backup program… Read More »Better Backups: Decide What You’re Going To Back Up
Note: This is a backup of a QA over at Super User which was auto-deleted, so is preserved here for posterity. Users with >10k rep… Read More »QA: Is there a way to make a backup of the difference with DD or PV?
You have backups, right? — SuperUser’s chat room motto This started out as an intro to bup. Somewhere along the way it underwent a philosophical… Read More »Better Backups: Pick a System
tl;dr: Seems the quickest way of doing this was to fire up a VM, install mysql-server and mysql-client and browse that way. I have backups… Read More »Browsing MySQL Backups