
Extracting Info From RoR2 Videos: Concept
Decipherer of Symbols Context I love Risk of Rain (RoR), and it’s sequel Risk of Rain 2 (RoR2) even more. They fit all the pieces… Read More »Extracting Info From RoR2 Videos: Concept

Decipherer of Symbols Context I love Risk of Rain (RoR), and it’s sequel Risk of Rain 2 (RoR2) even more. They fit all the pieces… Read More »Extracting Info From RoR2 Videos: Concept
☑? ? ? (see footnote) tl;dr: there are two simple js / jQuery command you can run in the browser dev console to quickly uncheck… Read More »Speeding up unchecking the ‘notify subscribers’ button in YouTube

Is it available yet? Is it available yet? Is it available yet… Background One hundred and fifty days ago, CityFibre came and dug up my… Read More »An Automated Availability Checker

Make it pop Background For one my my recent Subscriber Crowns I had the need to quickly ‘enhance’ some images for a slideshow- make them… Read More »A Quick GIMP Script to ‘Pop’ an Image

With bonus LibreOffice content! Background I’ve been using pandoc for a few years now as part of my workflow in sending out minutes of a… Read More »Pandoc to docx: tips for myself
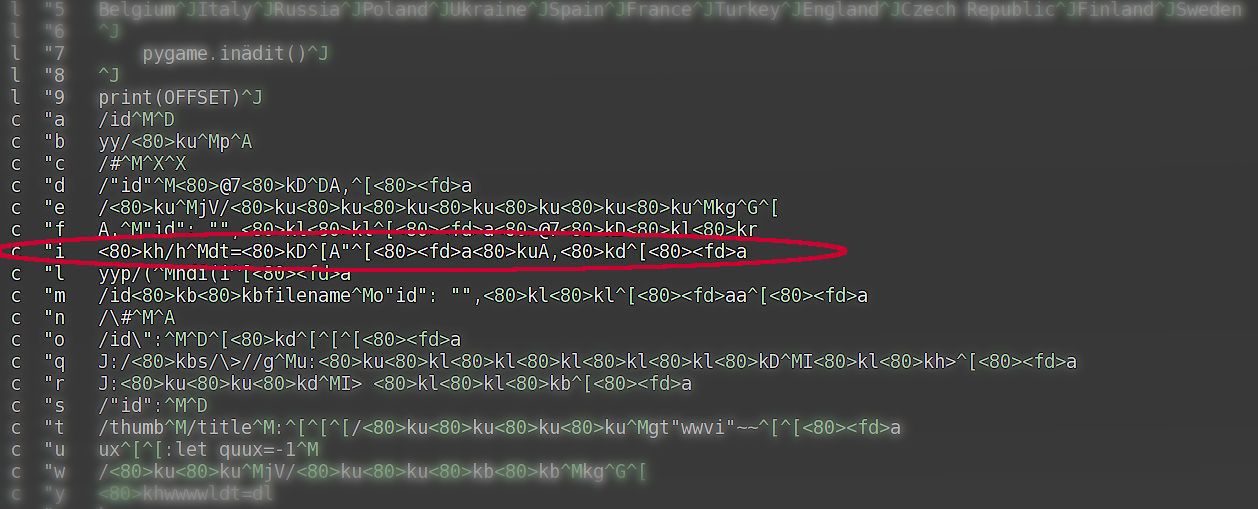
From ‘one-off’ to ‘actually I need to do this again…’ Context My often-talked-about video workflow has a bunch of useful features. For example, if I’ve… Read More »Converting Vim Macros to Functions

Working on the backlog Background Back in the summer of 2019 I streamed a Europa Universalis IV campaign as Aragon, where I went for the… Read More »Getting Aragon Videos Out
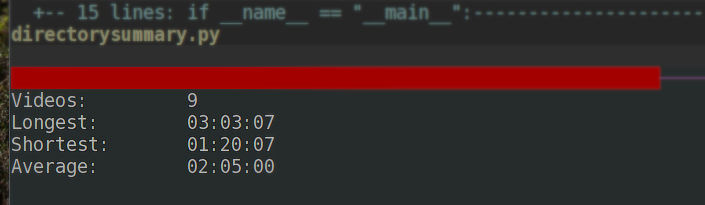
Information is power To process my Subscriber Crown videos for YouTube, I needed a little bit of information. I tend to split up longer videos… Read More »Quick Scripts: Summary of Video Directory

var TextFactoryInstance = new TextFactoryGeneratorInstantiator I want to speed up making text-that-follows-speakers videos in Blender, as it’s a bit tedious and repetitive to add all… Read More »Highlight Videos with Blender: A Text Object Generator?
tl;dr: use matrix-docker-ansible-deploy, you might be most interested in reading about the traefik aspect What’s All This About? I like Matrix for messaging / group… Read More »How to Quickly Set Up a Development Matrix Homeserver (with bonus Traefik routing)