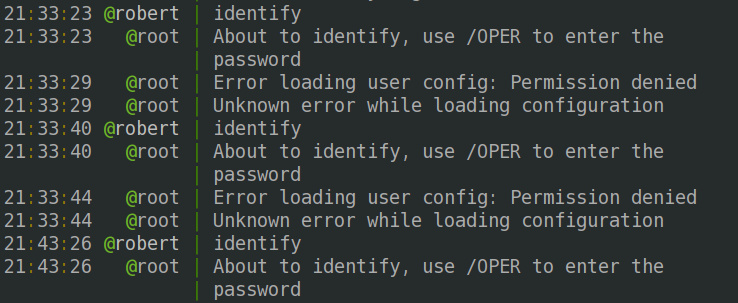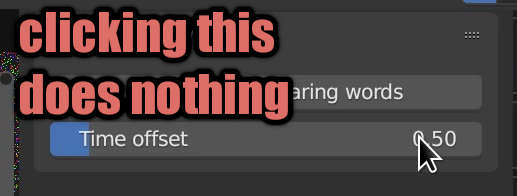
[solved] Why is my Blender addon panel property read only?

Read only, immutable, frozen, unchanging, static… just not working! tl;dr: Both the panel and the operator need access to any properties- using a PointerProperty to… Read More »[solved] Why is my Blender addon panel property read only?