
[fixed] ‘error invoking gcc driver’ (brew, macOS)
after updating homebrew Emacs Just let me get to ‘happy hacking!’, I beg you tl;dr, “I just want it fixed so I can get on… Read More »[fixed] ‘error invoking gcc driver’ (brew, macOS)

after updating homebrew Emacs Just let me get to ‘happy hacking!’, I beg you tl;dr, “I just want it fixed so I can get on… Read More »[fixed] ‘error invoking gcc driver’ (brew, macOS)
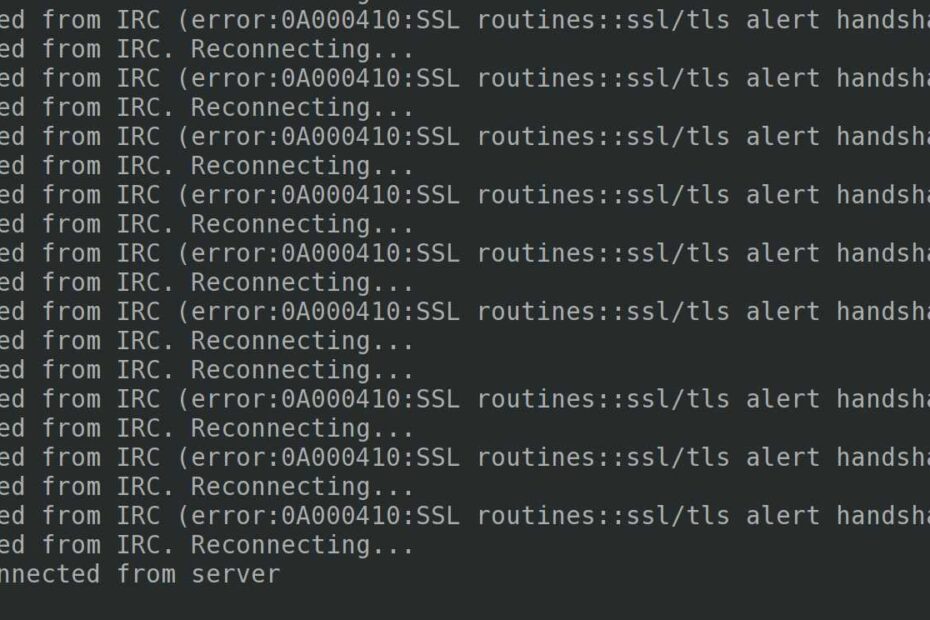
An internet connection issue lead to checking DNS lead to checking IRC lead to upgrading ZNC lead to a guntls / ssl issue lead to (FINALLY) a GitHub soluiton
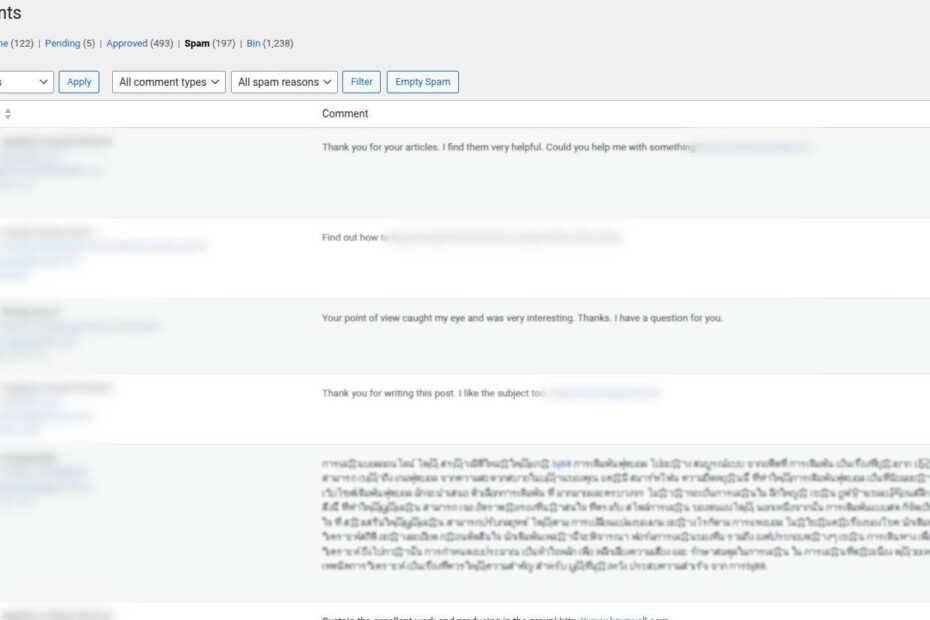
In the process of tweaking a thing or two behind the scenes, I changed how spam was being handled. Unfortunately Antispam Bee then started sending me a bunch of emails about the spam…

Hey, that’s not my site’s name! Obviously the solution is to add some schema, delicious schema.
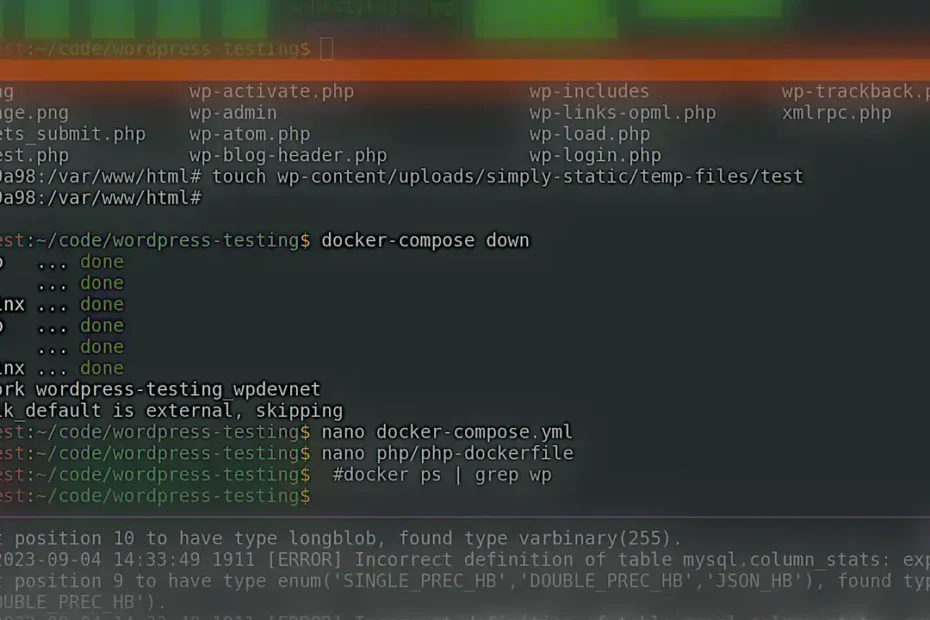
Static’d? Static-ified? Enstaticed? Context Previously, I “un-multisite’d” a few WordPress blogs I had running on Strider’s Virtual Multiblog (VMB). I used a plugin called Simply… Read More »Updating A Static’d WordPress Site

Exceptional Context I have been writing a userscript to add a description of a game to their entries on the Humble Bundle library page. Part… Read More »Humble Game Info Userscript: Handling Exceptions and Improving Consistency (Part 3)
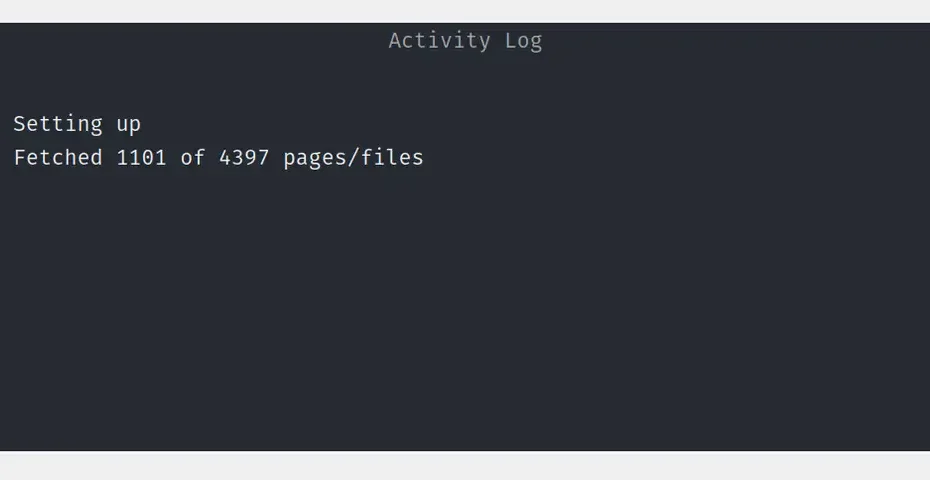
Calling me by someone else’s name Context You might be interested in the follow up post on updating an archived static WordPress site. I noticed… Read More »Fixing Site Issues (Multiblog, Default Site, & Speed)

Promise you will use Promises Context I am writing a userscript for the Humble Bundle library, so that it shows a game description below games… Read More »Humble Game Info Userscript: async, await and Promises (Part 2)
These look interesting, tell me more Background Way back in the mists of time in 2010 something cool happened. A new kid on the block… Read More »Humble Game Info Userscript: Concept and Starting From Scratch
There were many pits and I fell in them all Background Context In part 12 I mentioned the issue with storing operator properties in a… Read More »Quicker Text Editing in Blender (Part 13): CollectionProperty, KeyMapItem ID, Preferences Pitfalls