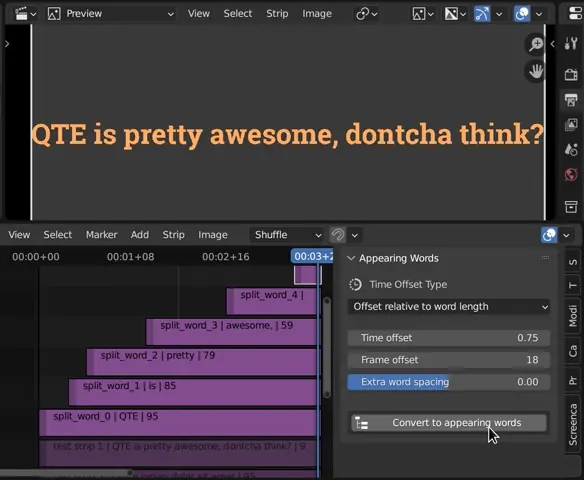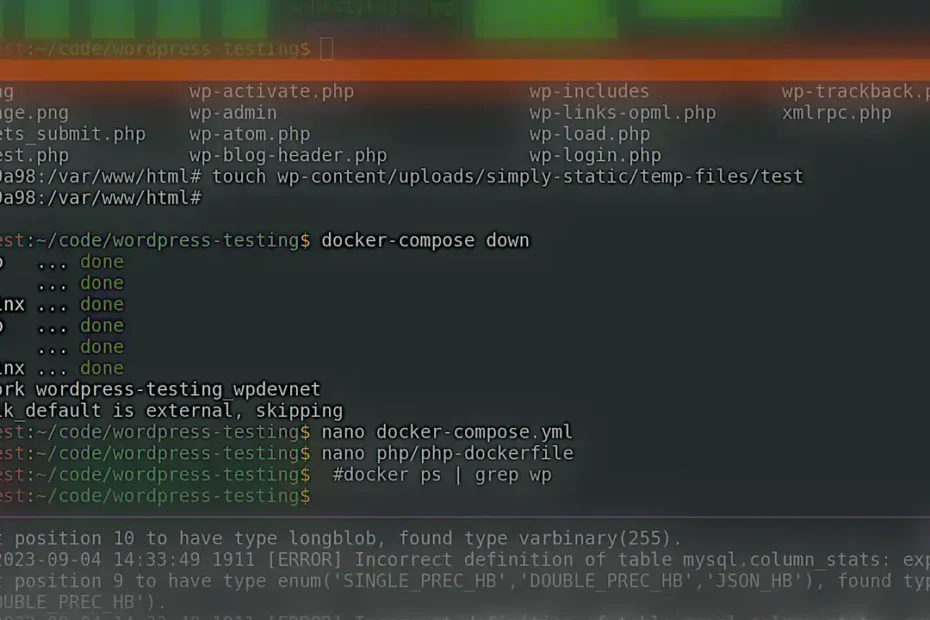
Updating A Static’d WordPress Site

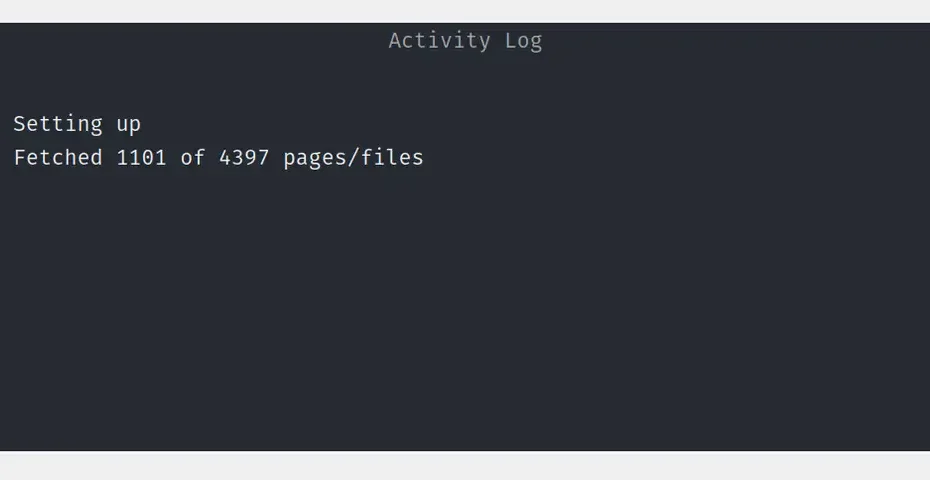
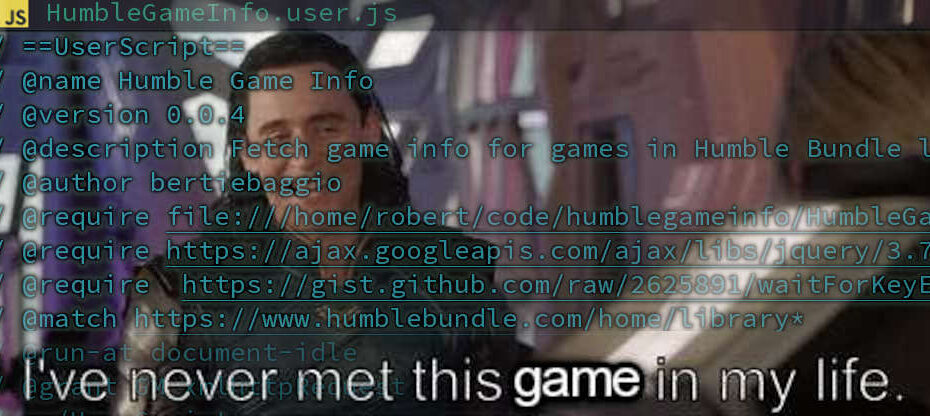
Static’d? Static-ified? Enstaticed? Context Previously, I “un-multisite’d” a few WordPress blogs I had running on Strider’s Virtual Multiblog (VMB). I used a plugin called Simply… Read More »Updating A Static’d WordPress Site